基于Hadoop的零售库存管理系统设计与实现
随着零售行业规模的不断扩大和数据量的急剧增长,传统库存管理系统的数据处理能力已难以满足现代零售商的需求。本项目基于Hadoop技术框架,设计并实现了一个高效、可扩展的零售库存管理系统,为计算机毕业设计提供了一个完整的解决方案。
一、系统设计背景与意义
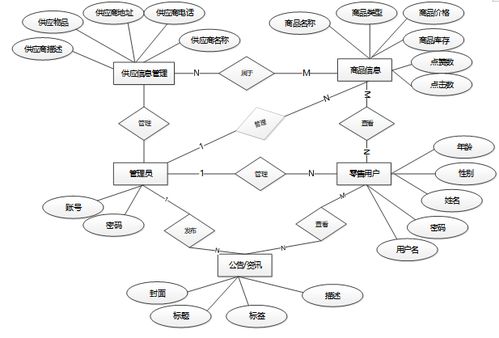
零售行业的库存管理涉及海量数据的采集、存储和分析,包括商品信息、销售记录、库存变动、供应商数据等。传统关系型数据库在处理这些数据时面临性能瓶颈,而Hadoop分布式架构能够有效解决这些问题。系统采用Hadoop生态系统中的HDFS进行数据存储,MapReduce进行数据处理,Hive进行数据查询分析,实现了对零售库存数据的高效管理。
二、系统架构设计
系统采用分层架构设计,主要包括数据采集层、数据存储层、数据处理层和应用层:
- 数据采集层:通过Flume和Sqoop工具实现多源数据的实时采集和批量导入
- 数据存储层:基于HDFS构建分布式存储系统,确保数据的安全性和可靠性
- 数据处理层:使用MapReduce编程模型实现库存预警、销售分析、补货预测等核心功能
- 应用层:提供Web管理界面,支持库存查询、报表生成、预警通知等功能
三、核心功能模块
- 库存实时监控:实时追踪库存数量变化,设置库存上下限预警
- 销售数据分析:基于历史销售数据,分析商品销售趋势和季节性规律
- 智能补货预测:结合销售预测和库存水平,自动生成补货建议
- 供应商管理:评估供应商绩效,优化采购策略
- 多维度报表:提供库存周转率、缺货率、滞销品分析等多种统计报表
四、技术实现要点
系统开发环境采用Hadoop 3.x版本,编程语言主要为Java,Web界面采用Spring Boot框架。关键实现包括:
- 设计合理的数据分区和压缩策略,优化HDFS存储效率
- 实现自定义MapReduce程序,处理复杂的库存分析逻辑
- 使用Hive建立数据仓库,支持灵活的数据查询
- 通过HBase实现快速随机访问,满足实时查询需求
五、系统优势与创新
相比传统库存管理系统,本系统具有以下优势:
- 高可扩展性:支持PB级别数据存储,可随业务增长线性扩展
- 高容错性:数据多副本存储,单点故障不影响系统运行
- 成本效益:使用廉价硬件构建集群,大幅降低IT成本
- 实时性:支持准实时数据处理,及时反映库存状态变化
六、应用前景与展望
本系统不仅适用于大型连锁零售商,也可为中小型零售企业提供SaaS服务。未来可结合机器学习算法,进一步优化预测精度;引入流处理技术,提升实时分析能力;整合物联网设备,实现更加智能的库存管理。
项目完整源代码已通过GitHub托管(项目ID:83957),包含详细部署文档和测试用例,为计算机专业学生提供了完整的毕业设计参考案例。通过本项目的学习与实践,学生能够深入掌握大数据技术在零售行业的应用,提升分布式系统开发能力。
如若转载,请注明出处:http://www.121drhero.com/product/34.html
更新时间:2026-01-12 20:45:20